前言
今天在看着 phar,一个朋友(工管类)突然问了我想爬取 App Store 上 App 的评论信息,问我有没有什么想法,看了一下手机端好像暂时没什么思路,毕竟没接触过移动端的,但是我发现 App Store 上 PC 端的网页就有,每个 App 都会有一个详细的页面,于是百度了一下 QQ,网易云什么的,注意到 url 上有 id 关键字,那猜测就是每个 app 都会有一个唯一的 id,测了一下,果真如此,那把它转化成网页就跟普通爬虫一样处理 HTML 的数据了。本来把思路摸清楚告诉朋友就算了,但我搜着搜着,突然发现苹果贴心地提供了 App 信息的接口!返回的是 json 格式的数据,这样就非常友好了,打算自己动手也试一试。
分析
首先当然分析的是 url 了,用 QQ 做例子:https://apps.apple.com/cn/app/qq/id444934666,后面的 id 换成指定 app 的 id,就会跳转到 app 的信息页面,有截屏,更新信息,介绍,评分和评论等。
然后我找到了这个友好的接口:
1
| https://itunes.apple.com/rss/customerreviews/page=页码/id=app的id/sortby=mostrecent/json?l=en&&cc=cn
|
这里参数 page 就是第一页、第二页之类的,测试了一下发现只能看见前10页,网页做出了限制:
CustomerReviews RSS page depth is limited to 10
一页大概 50 条左右,那就是只能爬取 500 条,不知道直接在详情页能刷出几条评论,没有去测。
参数 id 就是 app 的 id 了,获取 id方法大概有几种:
这个百度就有很多,不详细说了,贴一个参考博客:获取应用在AppStore的链接地址,从App中跳转到AppStore
直接在百度搜索 App Store 上的 "QQ",就能找到网页了
我又发现了苹果提供了一个搜索的接口:
1
| http://itunes.apple.com/search?term=app名称&entity=software
|
非常方便,返回的也是 json 数据,所有的搜索结果都在里面了,但有时候有一些返回的结果不够精确,比如搜 网易云音乐 在搜索结果里面并没有网易云音乐这个 app,只有一些相关的,这里只能做一个简单的参考,还是以方法1、2为精确查找。
环境
当然我们要写程序首先得确定需求:
- 获取 app id
- 获取 app 评论
- 对 json 数据进行操作
- 为了方便保存,可以保存在一个 excel 表里
所以大致需要的模块有:
1
2
3
4
| import requests
import json
import time
import openpyxl
|
因为给了接口,所以实现也不难(不然我才不会去写)。
只有 openpyxl 不是内置模块,因此使用前先
具体怎么使用百度或者谷歌看看文档就可以了。
编写
获取 App ID
为了方便使用,做了一点交互,输入名字来搜索,它返回的是毫无格式的 json 数据,放到 www.json.cn 美化一下格式看看,可以看到有 resultCount ,搜索的结果数量:

然后找到最关键的有 id 和 name:
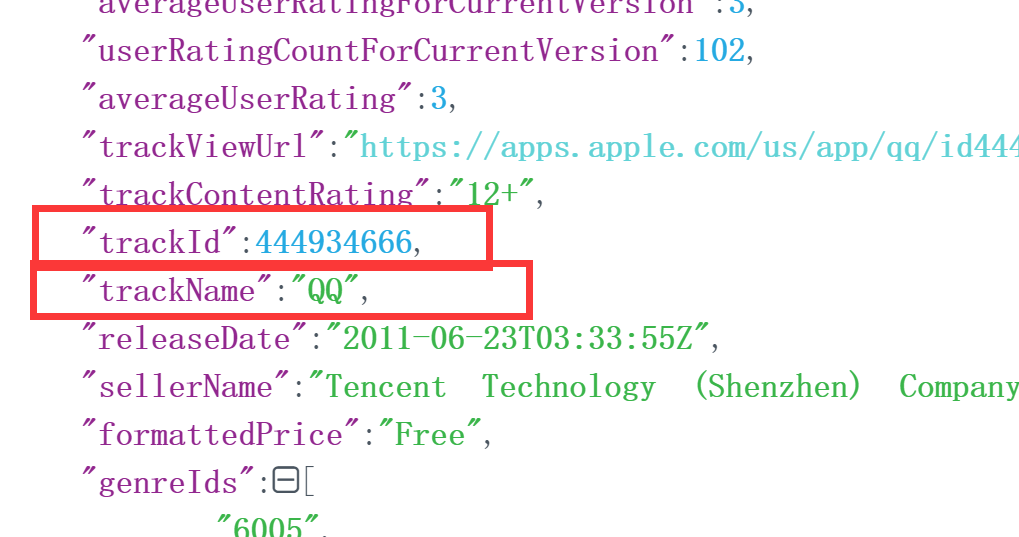
有就够了,把解析到的数据用 json.loads 处理一下,用 type(data) 可以看到是字典类型,那么取 key 为 trackId 和 trackName 出来。
效果:
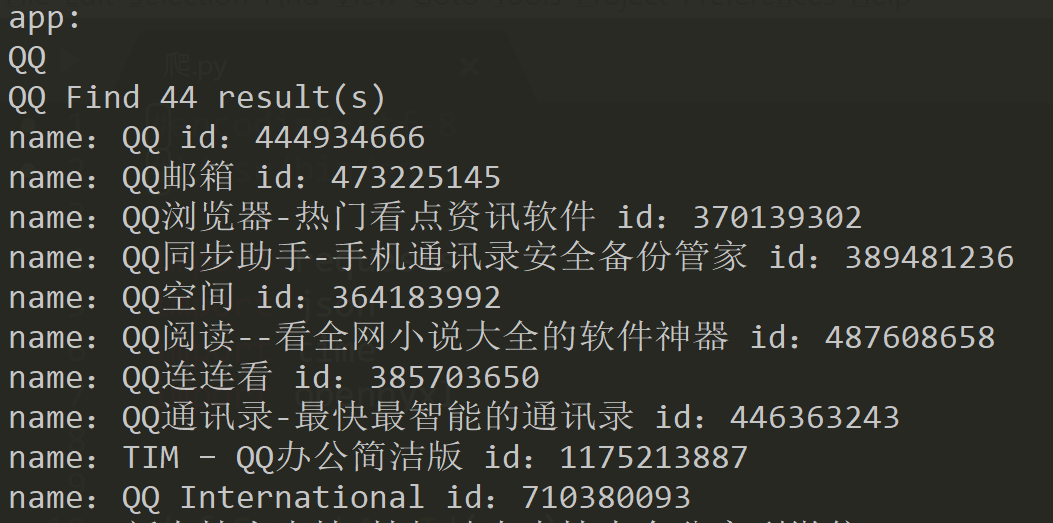
如果搜索不到的话就直接精确搜索,主要逻辑代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| def SearchAppId(app):
url = "http://itunes.apple.com/search?term=" + app + "&entity=software"
r = requests.get(url)
html = r.content
html_doc = str(html, 'utf-8')
data = json.loads(html_doc)
resultCount = data['resultCount']
results = data['results']
print(app + " Find " + str(resultCount) + " result(s)")
for i in range(resultCount):
name = results[i]['trackName']
app_id = results[i]['trackId']
print("name:" + name, "id:" + str(app_id))
|
建立表格
我们得用 openpyxl 模块初始化好表格再往里写数据,初始化代码:
1
2
3
4
5
6
7
8
|
wb = openpyxl.Workbook()
ws = wb.active
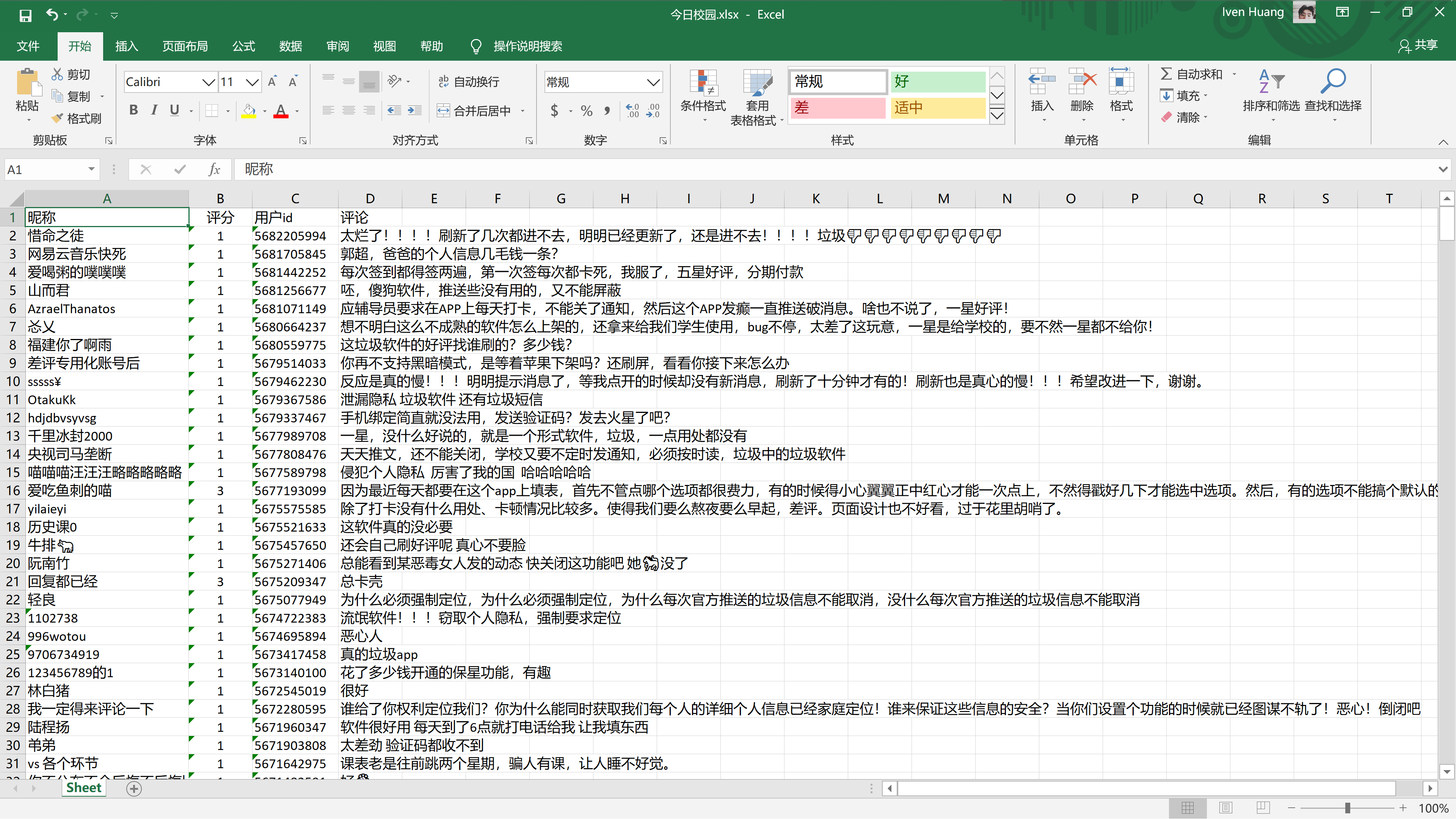
ws.cell(row=1, column=1, value="昵称")
ws.cell(row=1, column=2, value="评分")
ws.cell(row=1, column=3, value="用户id")
ws.cell(row=1, column=4, value="评论")
|
获取 App 评论
我们同样在接口拿到数据后美化一下格式,分析一下数据的结构:

可以看到在字典的 feed 里的 entry,里面是一个 list,里面就是每个人的信息了。
继续分析,我们看到需要提取的数据:

- 昵称在
author 中 name 的 label 中
- 评分在
im:rating 的 label 中
- id 在
id 的 label 中
- 评论在
content 的 label 中
于是就可以处理并写入表格了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def SaveContent(id, wb, ws):
row = 2
for j in range(1, 11):
url = "https://itunes.apple.com/rss/customerreviews/page=" + str(j) + "/id=" + str(id) + "/sortby=mostrecent/json?l=en&&cc=cn"
r = requests.get(url)
if r.status_code == 200:
html = r.content
html_doc = str(html, 'utf-8')
data = json.loads(html_doc)["feed"]["entry"]
for i in data:
name = i['author']['name']['label']
rate = i['im:rating']['label']
user_id = i['id']['label']
content = i['content']['label']
ws.cell(row=row, column=1, value=name)
ws.cell(row=row, column=2, value=rate)
ws.cell(row=row, column=3, value=user_id)
ws.cell(row=row, column=4, value=content)
row = row + 1
print(name, rate, user_id, content)
else:
return
time.sleep(2)
|
完整代码
封装一下,在 main 调用函数,传个参进去,最后再保存一下 xlsx 文件即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import requests
import json
import time
import openpyxl
def SearchAppId(app):
url = "http://itunes.apple.com/search?term=" + app + "&entity=software"
r = requests.get(url)
html = r.content
html_doc = str(html, 'utf-8')
data = json.loads(html_doc)
resultCount = data['resultCount']
results = data['results']
print(app + " Find " + str(resultCount) + " result(s)")
for i in range(resultCount):
name = results[i]['trackName']
app_id = results[i]['trackId']
print("name:" + name, "id:" + str(app_id))
def SaveContent(id, wb, ws):
row = 2
for j in range(1, 11):
url = "https://itunes.apple.com/rss/customerreviews/page=" + str(j) + "/id=" + str(id) + "/sortby=mostrecent/json?l=en&&cc=cn"
r = requests.get(url)
if r.status_code == 200:
html = r.content
html_doc = str(html, 'utf-8')
data = json.loads(html_doc)["feed"]["entry"]
for i in data:
name = i['author']['name']['label']
rate = i['im:rating']['label']
user_id = i['id']['label']
content = i['content']['label']
ws.cell(row=row, column=1, value=name)
ws.cell(row=row, column=2, value=rate)
ws.cell(row=row, column=3, value=user_id)
ws.cell(row=row, column=4, value=content)
row = row + 1
print(name, rate, user_id, content)
else:
return
time.sleep(2)
def main():
app = input("app:\n")
SearchAppId(app)
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(row=1, column=1, value="昵称")
ws.cell(row=1, column=2, value="评分")
ws.cell(row=1, column=3, value="用户id")
ws.cell(row=1, column=4, value="评论")
id = input("input app's id:\n")
SaveContent(id, wb, ws)
wb.save(app + ".xlsx")
print("Done!")
if __name__ == '__main__':
main()
|
效果图:
搜 id:
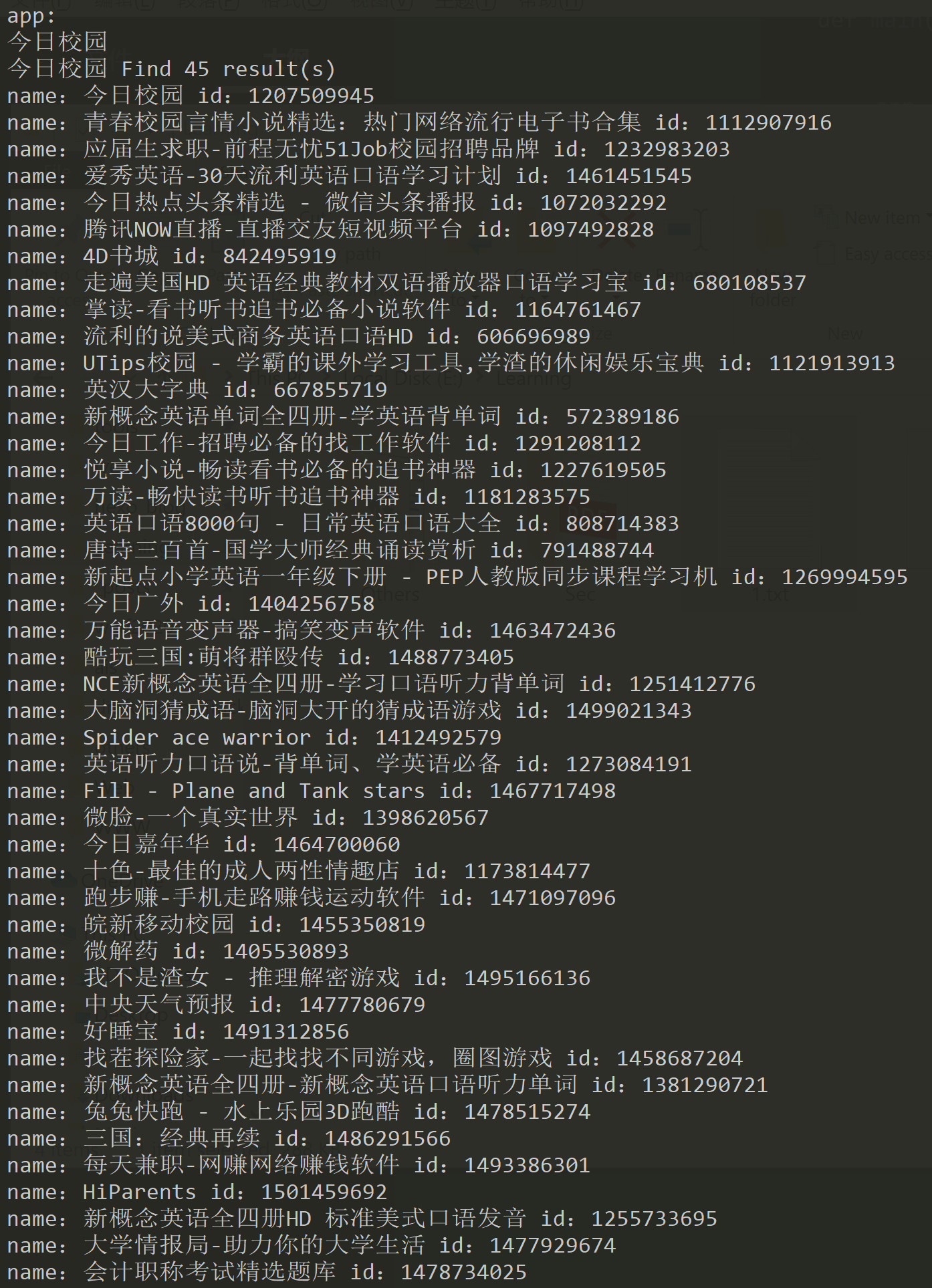
爬取评论并保存:
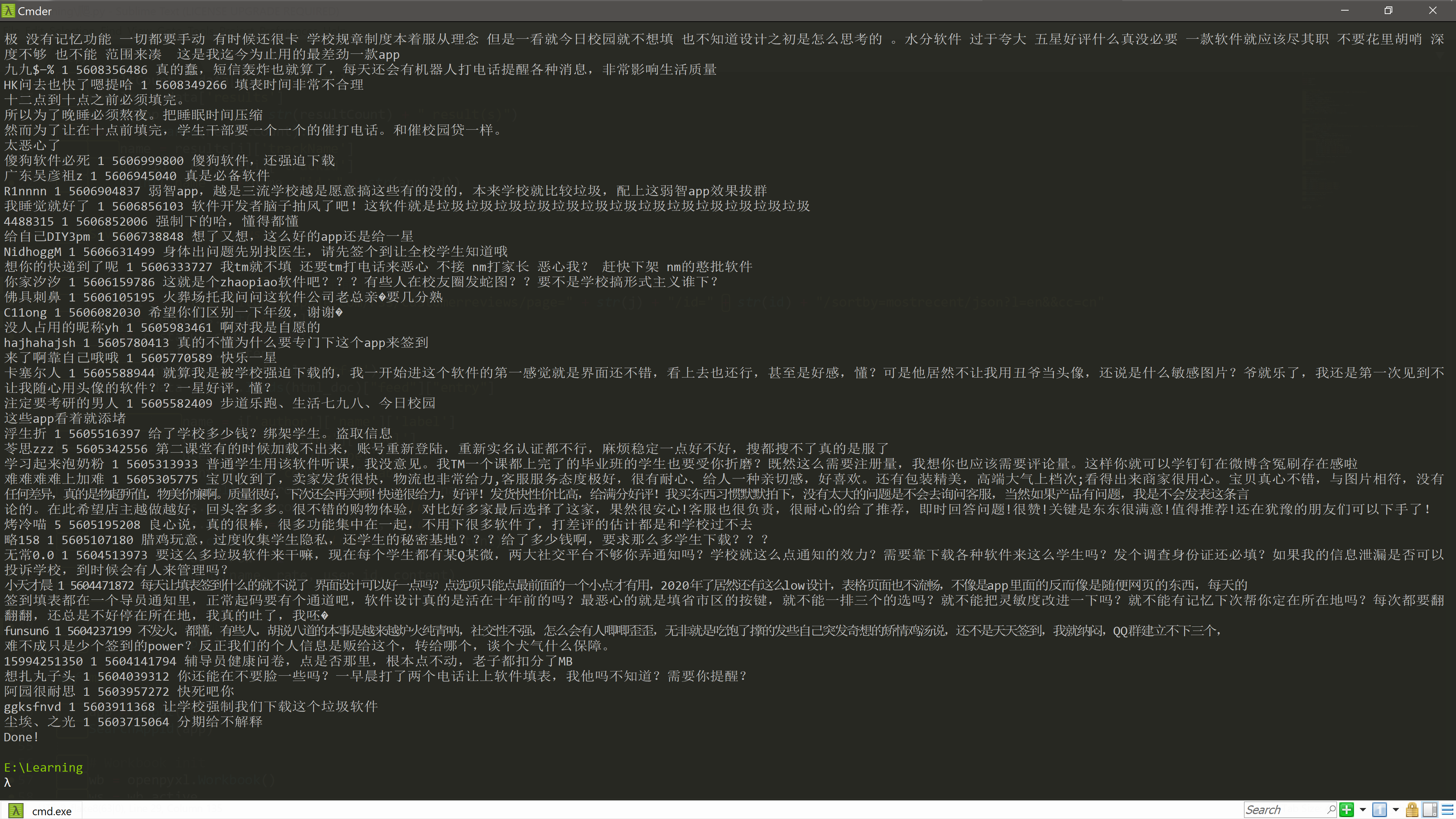
Done!
我们可以看到当前目录生成了文件:

数据效果图: